如何用Linux命令删除空行 | 技巧
导言: 从简单需求开始学习掌握命令行黑魔法。
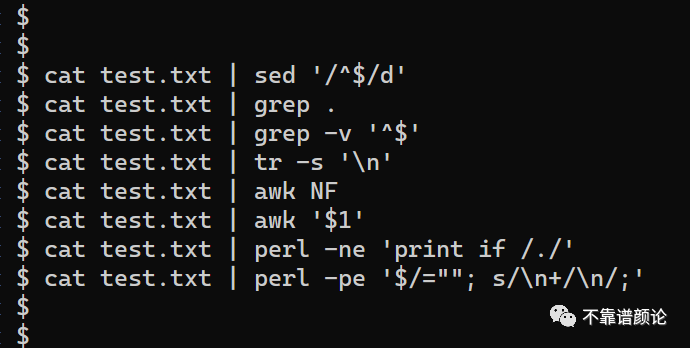
今天遇到一个实际需求:把文本文件中的空行全部删掉。
这个其实很容易实现。如题图所示,常见的sed、grep、tr、awk、perl命令都可以用来解决此问题。
下面就分别解释下每个命令:
|
|
解释: 命令sed是按行进行文本处理的,从输入文件依次读入每一行,处理后进行输出。命令sed的参数,两个“/”之间是正则表达式“^$”。其中“^”表示行首,“$”表示行尾,所以,“^$”表示空行。末尾的“d”表示删除,即匹配了该正则表达式的行(即空行),将进行删除。
|
|
解释: 命令grep是在文本中进行搜索,缺省是把匹配的行进行输出。上面命令中,其唯一参数是半角点号“.”,表示匹配任何字符。这个搜索,正好就是表示非空行。其结果就是把空行删掉了。
|
|
解释: 这是用命令grep反向进行搜索,参数“-v”表示匹配的行不输出,仅输出未匹配的行。如前所述,正则表达式“^$”表示空行,所以上述命令就是把非空行的内容进行输出。
|
|
解释: 命令tr是进行字符替换,而它有个便利的参数“-s”,用来表示去除重复的指定字符。“\n”表示回车符,是文本文件的换行(这里需要注意 Windows 和 Linux 的文件在换行时有细微差别,如果结果不符合预期,可以尝试用dos2unix或unix2dos命令进行换行格式切换)。上述命令表示,如果遇到连续的多个“\n”(如“\n\n”),则将其替换成单个“\n”,于是就达到了去除空行的效果。
|
|
解释: 命令awk本身是个功能强大脚本语言,其基本处理模式也是按行进行的。依次读取输入文件的每一行,解析并做计算,缺省情况下,会根据计算结果,为真(即非 0 值)时,将该行内容输出。效果上类似于grep,但匹配能力显然要强大许多,可以支持非常复杂的逻辑。这里仅使用“NF”这样一个表达式,它表示对这一行以空白字符(包括空格和制表符“\t”)进行拆分,拆分后的项数目。所以,一旦有任何非空白字符(即非空行),该NF将为正整数,否则其值为 0。所以,结果还是仅输出了所有非空行。
|
|
解释: 这个命令与上一个命令类似,也是由awk进行解析,不过其判断条件由“NF”换成了“$1”,后者表示拆分后的第一项。自然,它若为空,就表示当前行为空行。最终效果也与上面相同。
|
|
解释: 这是用perl脚本语言来实现功能,perl相比awk而言,由于有各种支持库辅助,功能更加强大,常用来编写各种工具。上面的参数“-ne”是“-n -e”的缩写(关于perl命令行参数的解释,可以运行“perldoc perlrun”查看)。“-n”表示按行处理文本,类似于上面的sed和awk的模式。“-e”表示后面的字符串是perl脚本内容。perl语言中,if语句有两种写法:“语句 if 条件”和“if (条件) { 语句; }”,这里用了前一种简便写法。而条件“/./”,两个斜杠表示中间是正则表达式,所以这里其实还是与“grep .”相同的原理。
|
|
解释: 这是使用perl来删除空行的另一种实现。同前,“-pe”是“-p -e”的缩写,“-e”已经解释过,是表示后面字符串为脚本。“-p”与“-n”类似,也是让perl按行处理,不过在处理完成后,它会自动打印处理结果。简单说,“perl -n”类似于“sed -n”,而“perl -p”类似于“sed”。然而,在后面的字符串中,包含了两个语句,前一句“$/=""”,它是对perl内置变量“$/”赋予空值,该变量是行分隔符,缺省是“\n”,赋予空值后,将导致perl的“按行处理”,变成一次性读取多行(遇到空行时会停下来,处理完再继续读取),这时多个连续空行就会放入一个字符串,被下一条语句“s/\n+/\n/”进行替换。“s/源字符串/目标字符串/”是正则表达式的替换语法。“\n+”中的“+”则表示前面的“\n”应该有一个或多个。
至此,几个命令解释完成。下面,稍微变换下需求:如果是想把连续多个空行,删掉重复,保留单个空行,例如下面的文件:
|
|
处理后成为:
|
|
该怎么用上述sed、awk或perl等命令来处理呢?
不妨思考思考,咱们下次揭晓答案。
注:本文首发表于“不靠谱颜论”公众号,并同步至本站。