如何导出与ChatGPT的聊天记录
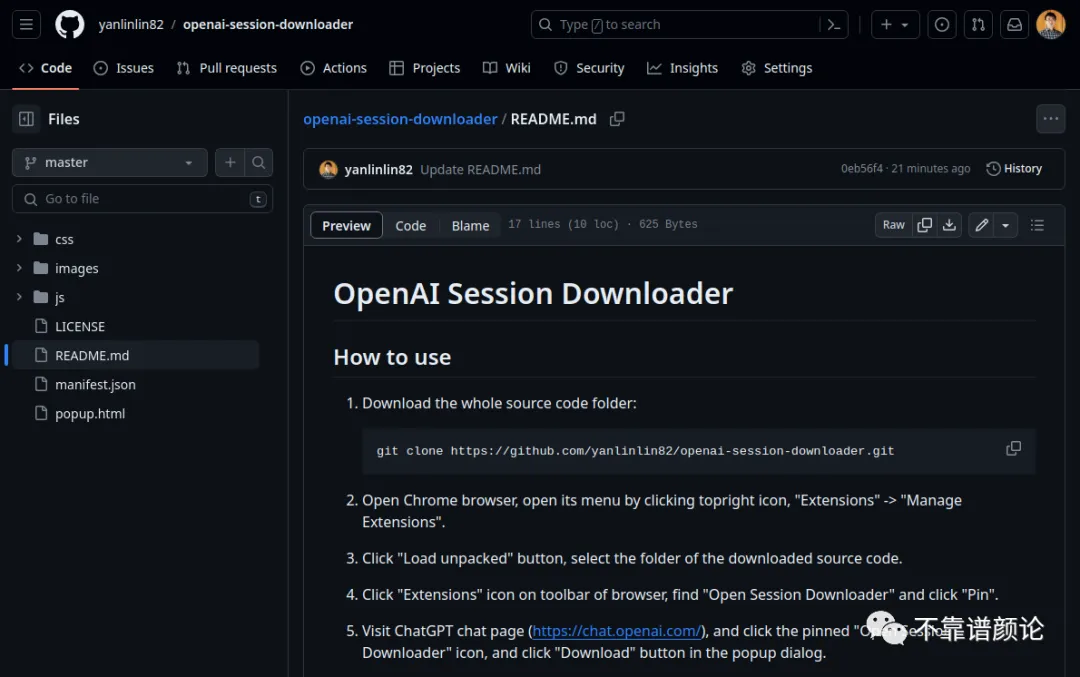
Image 最近,我频繁地跟ChatGPT聊天。AI给出的很多回答,感觉都挺不错。所以,萌生了把聊天记录保存下来的想法。但我发现,似乎只能一条条地进行复制粘贴。这真太不符合ChatGPT作为一个效率工具的设定了。
于是,在我的循循诱导下,ChatGPT帮我找到了合适的解决方案:写一个Chrome浏览器插件(extension),以浏览器中“所见即所得”的方式,把内容提取出来,并以markdown格式,保存到本地文件中。
具体的“教唆”过程,我就不详细展示了。这里只说下结果。有需要(下载ChatGPT聊天记录)的,可以参考如下操作进行:
从GitHub下载插件源代码(点击文末“阅读原文”可以跳转到该GitHub仓库)。下图以Linux系统为例,展示了使用git命令获取源码的过程:
Image
打开Chrome浏览器,点击右上角的“…“,打开应用程序的菜单,选择其中的“Extensions” -> “Manage Extensions”。在打开的插件管理界面上方,可以看到“Load unpacked”按钮,点击该按钮,根据提示选取刚才下载源码所保存的目录,即可安装该插件。
Image
安装完成后,在插件列表中将看到“OpenAI Session Downloader”,如下图所示:
Image
点击工具栏上的“Extensions”图标,从中找到“OpenAI Session Downloader”,点击那个图钉(鼠标移动上去将提示“Pin”)按钮,以便将该插件固定展示在工具栏上。
Image
重新打开ChatGPT网站(https://chat.openai.com/,如已打开,需要刷新页面,使插件生效)。此时点击工具栏中的“OpenAI Session Downloader”图标,该插件会弹出一个附在图标旁边的小窗口,如下图所示。
Image
在弹出的小窗口中,点击其中的“Download”按钮。浏览器会弹出文件保存提示对话框,选择需要保存的文件路径及名称即可。
Image
该文件为markdown格式,使用任何一个文本编辑工具(如VScode)打开阅读即可:
Image
上述过程,采用的是本地未打包(unpacked)方式进行的插件安装。这种模式,通常是提供给开发者使用的。我之所以暂时没把这个插件正式打包发布,主要是因为这种最简单粗暴的方法,已足够解决问题。而且,由于内容的提取很大程度上依赖于目标网页的具体实现(包括所采用的HTML标签、属性及其层次结构),这些很可能会在未来频繁变更。保持插件代码不打包,用户可以随时打开源码进行调整,以适应最新情况,获取正确的数据。
这里使用的数据爬取技能,是通过浏览器插件形式,让自己的“爬虫”代码植入目标网页中去,通过DOM直接操作并获取数据,绕开了复杂的登录认证和解密等过程。这种方式,不仅能用于导出ChatGPT的聊天记录,也能用于其他很多从浏览器收集并整理数据的工作,可以说是数据工作者的重要甚至必要技能。
顺便提一句,这个插件的大部分代码(超过80%),都是由ChatGPT完成的,若不考虑昨天我在入门学习浏览器插件开发时所花掉的几个小时,我在这个项目(openai-session-downloader)上花费的时间,至多也就一两个小时。可见,ChatGPT作为效率工具,仍然是值得肯定的。
总之,多少会写点代码,加上有ChatGPT辅助,很多看似繁杂的需求,都能轻松快速搞定了。
注:本文首发表于“不靠谱颜论”公众号,并同步至本站。