为了“弱化”类型,C++有多拼?
1
众所周知,C++ 是一门强类型语言。也就是说,每个变量在使用前,都需要非常明确地定义清楚类型。变量类型,指的是所占内存空间大小(几个字节)、表示方式(字符、整数、浮点数、有无符号等)、存储模式(自动变量、静态变量、外部变量等;我在之前《现代C++学习笔记(4):auto的前世今生》一文对此有少许介绍)。
清晰定义变量类型,有助于写出性能尽可能高的代码。然而,这其实挺反人性的,尤其在变量很多的中大型程序中,光是反复书写类型,并确保赋值与定义类型相匹配,就是很大的负担。
这种负担在过去曾经更加沉重。回想“上古时代”的匈牙利命名法,变量名的前缀能体现变量类型,很便于代码阅读时,望文生义地理解其类型。至今 WIndows API 的函数声明中仍然可见此类表达:
|
|
然而其缺点在于,一旦需要调整变量类型,就得把通篇该变量名批量替换为新类型前缀。
2
相比之下,JavaScript 之类的弱类型语言,统一的函数定义,根据赋值内容自动调整变量类型,简直就是“傻瓜式优质待遇”:
|
|
于是,C++11 起,我们有了auto:
|
|
当然,C++ 没有因为“妥协”于这样的使用便利,而退化为“弱类型语言”。它仍然保留了强类型语言的本质,在上述代码编译过程中,会自动根据上下文,推断出正确的类型。强类型语言的优势仍然存在,减轻的是使用者的编程负担。
3
相对困难些的,是把结构体进行“弱类型化”。
日常编程过程中,我们经常需要把两个或多个变量组合起来使用,比如平面坐标(组合x和y)、立体空间坐标(组合 x、y和z)、RGB 颜色(组合r、g和b三个分量)。传统的做法,我们都需要很正式地“吟诵”出:“struct blablabla ...”。
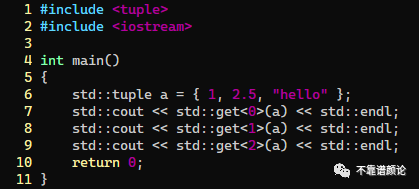
在 C++ 自带的标准模板库 STL 中,为此贴心地设计了一个神器:std::tuple。下面用一个例子简单进行展示:
|
|
放在过去,实现上述代码,不得不单独定义一个结构体:
|
|
而到了 C++17 标准,对上述“临时组合类型”的定义,甚至可以简化到不需要写具体类型,而仅由后面的初始化表达式来决定:
|
|
代码大为简化,用起来更像“弱类型语言”了。
4
其实上述封装思想,在只有两个元素时,专门有一个std::pair进行支持,该类型也是我们最常用的映射类型(或者说字典类型)std::map的实现基础。std::tuple可以说是std::pair的泛化,允许自动形成任意多个元素的组合类型。
C++17 标准提供的“省略模板参数”的写法,也为std::map的使用,带来了超级便利:
|
|
5
此外,在未来的 C++ 标准中,std::tuple很可能还会像其他容器类型一样,允许进行迭代访问(目前还不支持,但已经有类似的提案了):
|
|
而如果能够支持,这种“根据组合类型展开,可预见到循环的次数及对应类型”,将成为“编译期循环语法”,这可是原生的 struct结构体所不具备的“惊喜”。像是具备“反射(reflection)”功能的 Java 或 C# 语言,但其实一切“魔法”都在编译期发生,确保了运行时的程序效率,这将是其他语言难以望其项背的。
当然,在这个新标准提案被采纳之前,还是有一些借用可变参数个数模板机制来实现上述功能的尝试。具体可参见 C++ Stories 网站上的两篇新文章,很有趣的“魔法秀”:
- https://www.cppstories.com/2022/tuple-iteration-basics/
- https://www.cppstories.com/2022/tuple-iteration-apply/
注:本文首发表于“不靠谱颜论”公众号,并同步至本站。